How transformers
Translate or Sort?
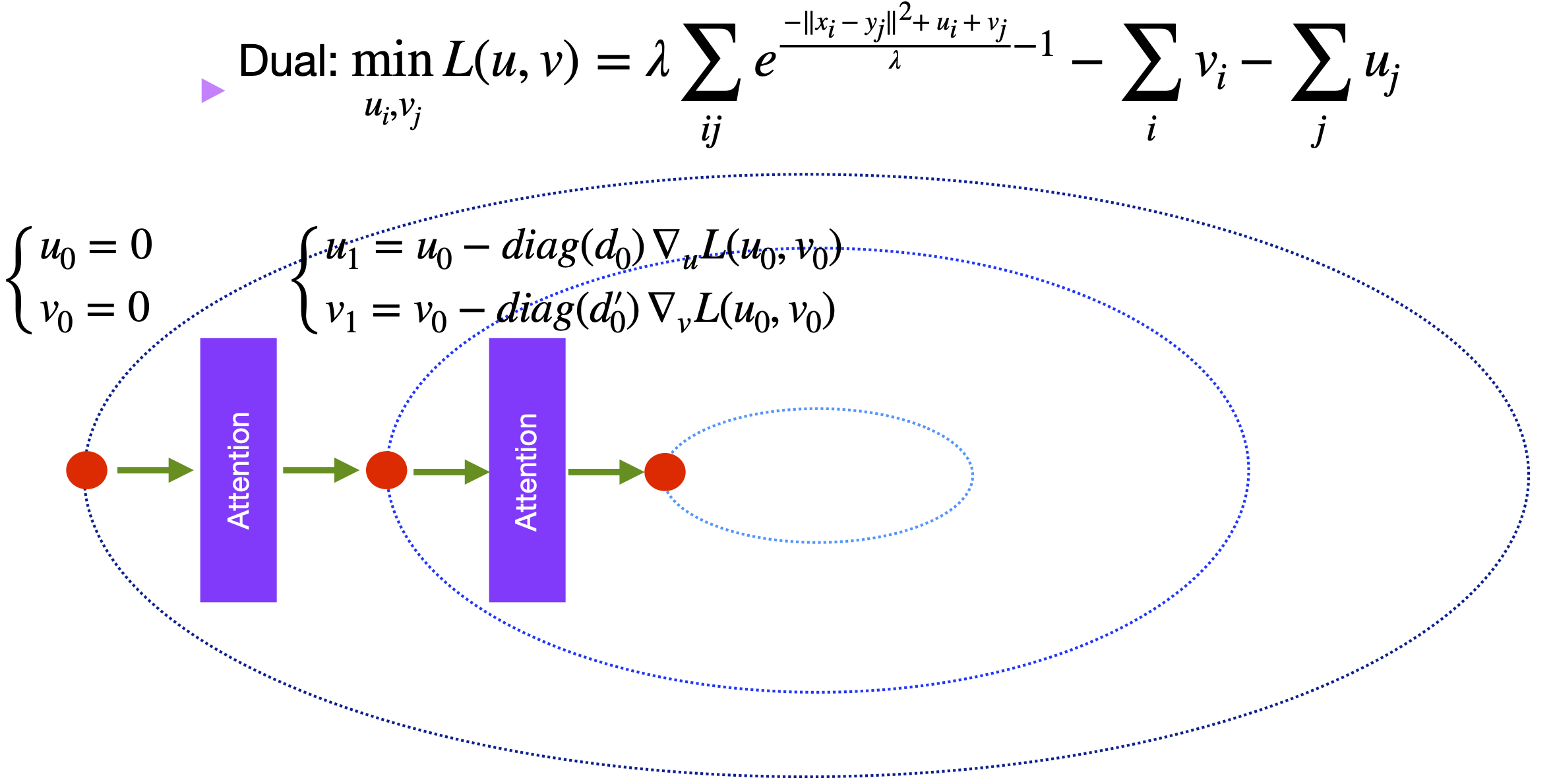
In-context learning (ICL), an emerging capability of large language models that enables them to perform statistical inference at test time without parameter adaptation. Current theoretical studies of in-context learning often study the mechansim of statistical learning such as supervised learning. We aim to study the mechansim of in-context learning for langauge translation which is more closely aligned with main application of LLMs for NPL. Our study is based on discrete optimal transport theory, namely solving the following linear program [Cuturi 2013] $$ P_\lambda = \arg \min_{P} \sum_{i=1}^n \sum_{j=1}^n\| x_i - y_j \|^2 P_{ij} + \lambda\underbrace{\sum_{i=1}^n \sum_{j=1}^n P_{ij} \log(P_{ij})}_{-\text{entropy regularization}} \; \text{subject to $P$ is a doubly stochastic matrix}$$ where \( x_1, y_1, \dots, x_n, y_n \in \mathbb{R}^d \). OT has many applications from sorting to cell perturbation analysis in Bioinformatics. Here, we show that OT can also be used to explain the internal mechansim of LLMs for tranlsation.
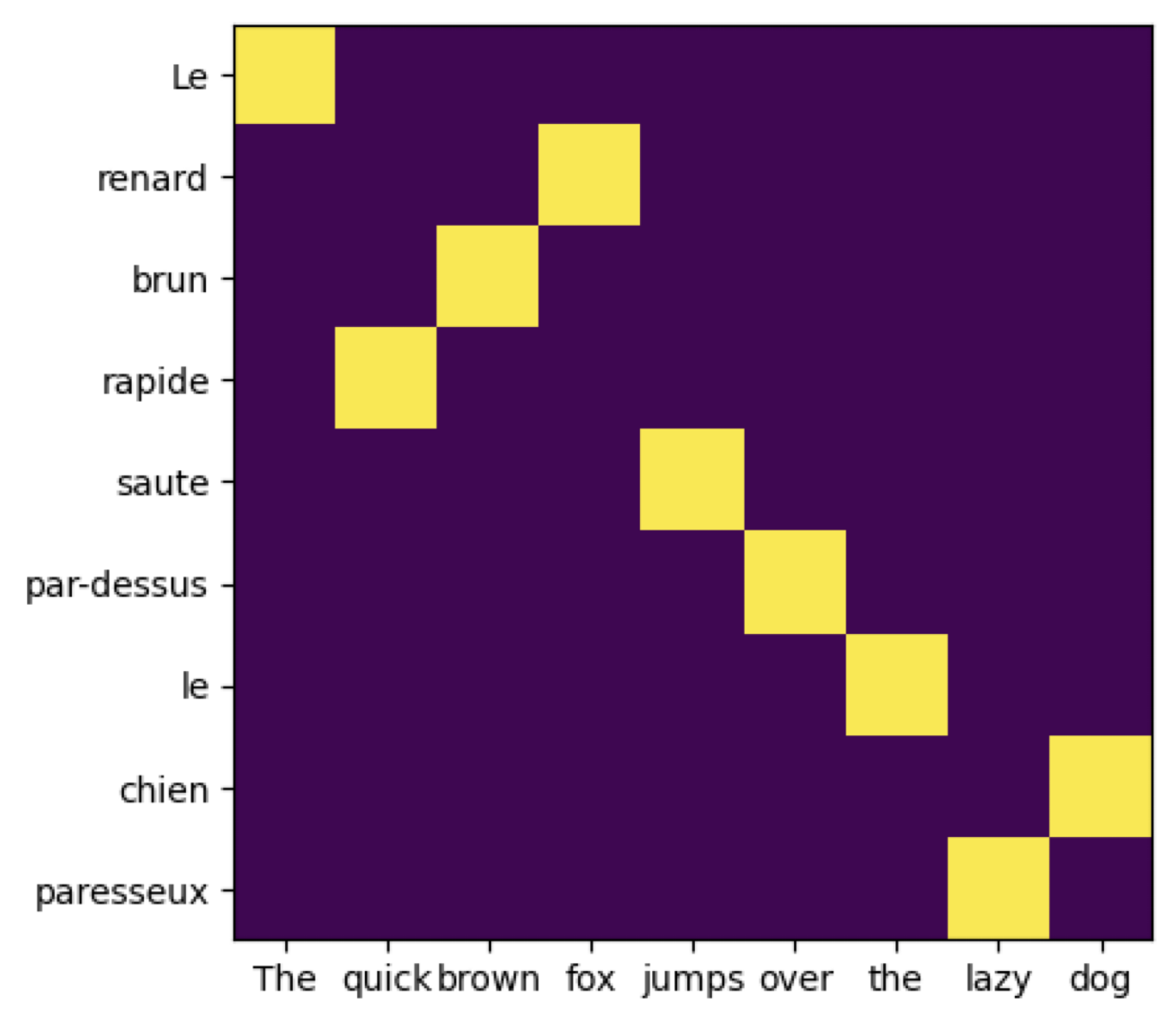
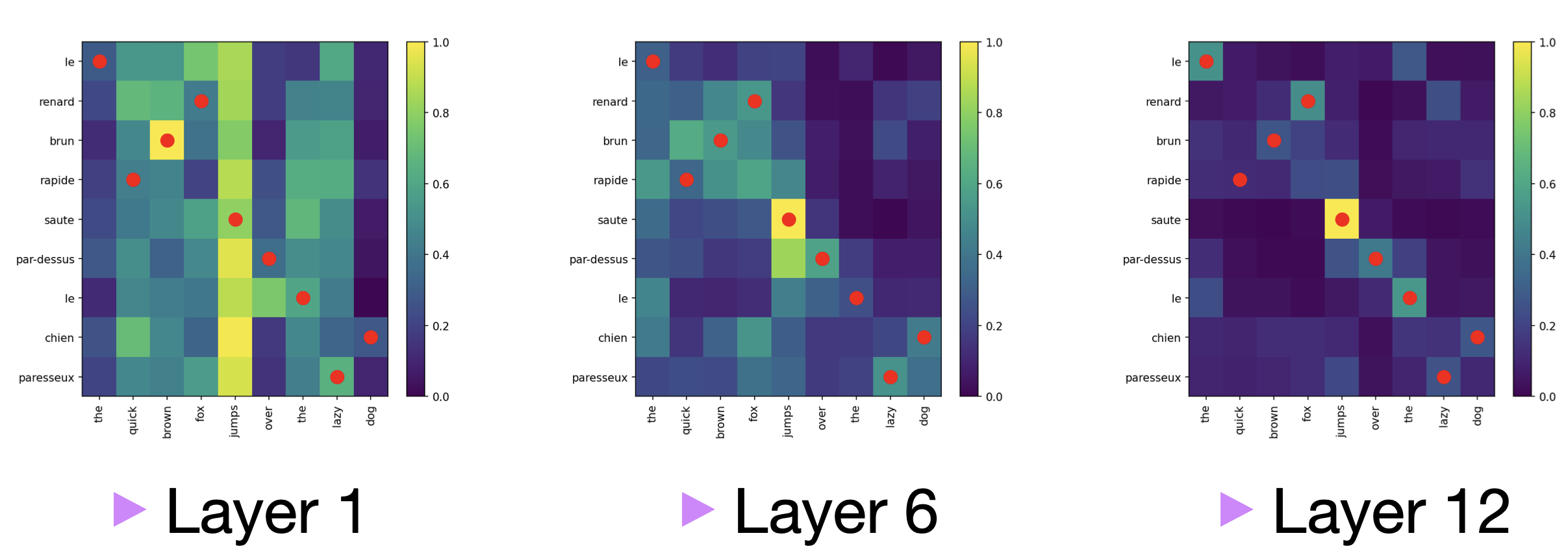
Observation: OT and Translation. The following plot shows the solution of OT ( \( P_0 \)) when \( x_i, y_i\) are word embeddings of English and French words respectively in the first layer of BERT multilingual pre trained model.